회의날짜 : 01/16 목요일
회의장소 : 능곡역 지노스카페
최적화란?
신경망 학습의 목적은 손실 함수의 값을 가능한 낮추는 매개변수 즉 가중치와 편향을 찾는 것 입니다.
이는 곧 매개변수의 최적값을 찾는 문제이며 이러한 문제를 푸는 것을 최적화라고 합니다.
경사하강법의 종류

전체 training set을 사용하는 것을 Batch Gradient Descent 라고 합니다.
그러나 이렇게 계산을 할 경우 한번 step
을 내딛을 때 전체 데이터에 대해
Loss Function을 계산해야 하므로 너무 많은 계산량이 필요하게 되고
이를 방지하기 위해 보통은 Stochastic Gradient Descent (SGD) 라는 방법을 사용합니다.
전체 데이터(batch) 대신 일부 조그마한 데이터의 모음(mini-batch)에 대해서만 loss function을 계산하며
이 방법은 batch gradient descent 보다 다소 부정확할 수는 있지만,
훨씬 계산 속도가 빠르기 때문에 같은 시간에 더 많은 step을 갈 수 있으며
여러 번 반복할 경우 보통 batch의 결과와 유사한 결과로 수렴하게 됩니다.
또한, SGD를 사용할 경우 Batch Gradient Descent에서 빠질 local minima에 빠지지 않고
더 좋은 방향으로 수렴할 가능성도 있습니다.
Gradient Descent 알고리즘의 계보
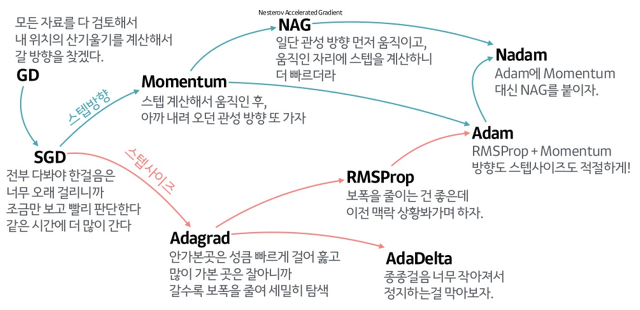
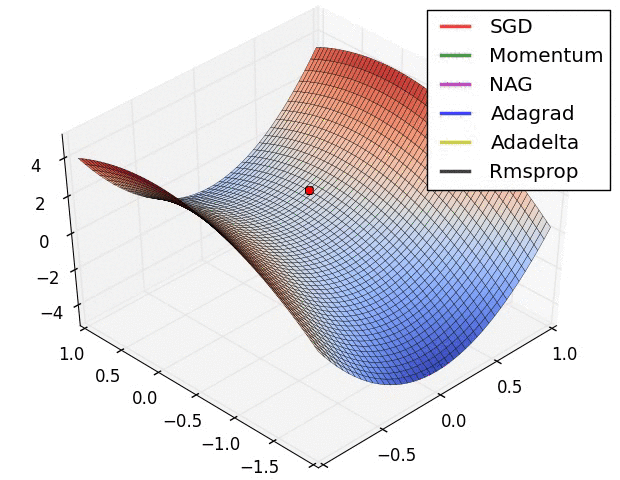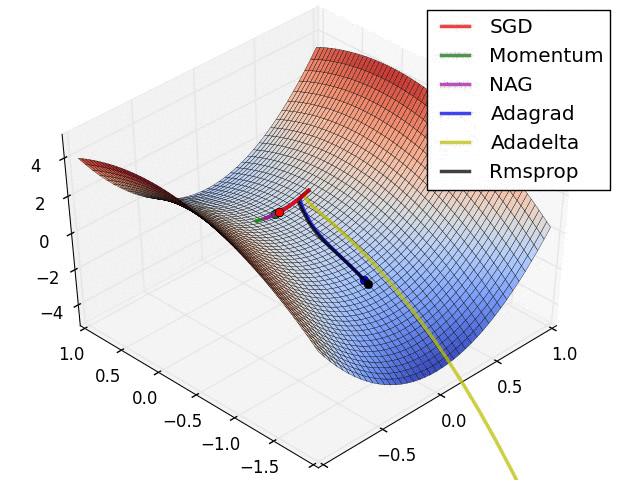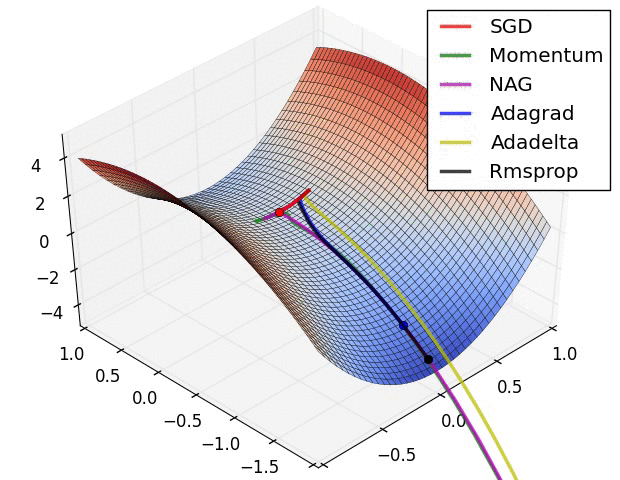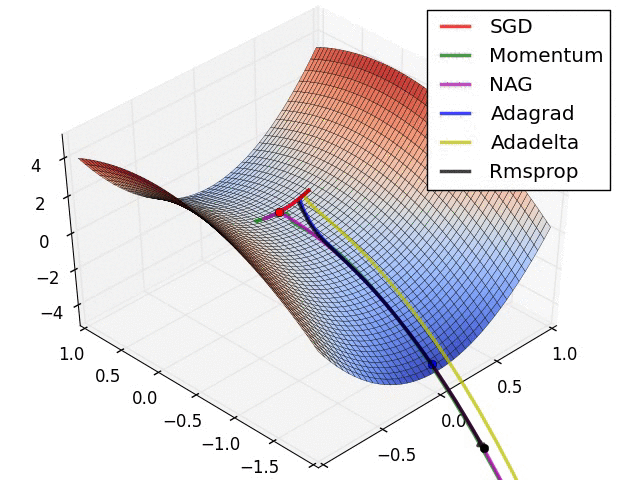
알고리즘의 성능비교
Momentum 과 NAG의 차이
Momentum은 그냥 gradient를 계산해서 parameter를 update 하지만 NAG는 가중치를 일부 update하고 그지점에서 gradient를 계산하기 때문에 update가 더 빠르다.
AdaGrad의 단점
gradient의 제곱의 합의 root를 분모로해서 gradient에 곱해서 parameter를 update해주기 때문에
어느순간 update가 되지 않기 때문에 학습이 진행되지않는 순간이 온다.
AdaGrad의 단점을 극복을 어떻게 하는가
gradient의 제곱의 합을 분모로 하는것이 아니라 , gradient의 제곱의 지수평균을 분모로 해준다.
분모가 무한히 커지는것을 방지할 수 있다.
'ML > 머신러닝' 카테고리의 다른 글
| YOLO와 RCNN 분석 (0) | 2020.02.24 |
|---|---|
| Sliding window는 무엇일까?[object detection] (3) | 2020.02.24 |
| Hyperparameter vs Parameter 과 Bias and Variance Tradeoff 고찰 (0) | 2020.02.24 |
| Inception(GoogLeNet) (0) | 2020.02.24 |
| Resnet은 왜 잘 작동할까? (0) | 2020.02.24 |