

















로지스틱 회귀
독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는데 사용되는 통계 기법이다.
로지스틱 회귀의 목적은 일반적인 회귀 분석의 목표와 동일하게 종속 변수와 독립 변수간의 관계를 구체적인 함수로 나타내어 향후 예측 모델에 사용하는 것이다.
이는 독립 변수의 선형 결합으로 종속 변수를 설명한다는 관점에서는 선형 회귀 분석과 유사하다.
하지만 로지스틱 회귀는 선형 회귀 분석과는 다르게 종속 변수가 범주형 데이터를 대상으로 하며 입력 데이터가 주어졌을 때 해당 데이터의 결과가 특정 분류로 나뉘기 때문에 일종의 분류 (classification) 기법으로도 볼 수 있다.
흔히 로지스틱 회귀는 종속변수가 이항형 문제(즉, 유효한 범주의 개수가 두개인 경우)를 지칭할 때 사용된다.
이외에, 두 개 이상의 범주를 가지는 문제가 대상인 경우엔 다항 로지스틱 회귀 (multinomial logistic regression) 또는 분화 로지스틱 회귀 (polytomous logistic regression)라고 하고 복수의 범주이면서 순서가 존재하면 서수 로지스틱 회귀 (ordinal logistic regression) 라고 한다.[2] 로지스틱 회귀 분석은 의료, 통신, 데이터마이닝과 같은 다양한 분야에서 분류 및 예측을 위한 모델로서 폭넓게 사용되고 있다.
이항형 로지스틱의 회귀 분석에서 2개의 카테고리는 0과 1로 나타내어지고 각각의 카테고리로 분류될 확률의 합은 1이 된다.
첫 번째 차이점은 이항형인 데이터에 적용하였을 때 종속 변수 y의 결과가 범위[0,1]로 제한된다는 것이고 두 번째 차이점은 종속 변수가 이진적이기 때문에 조건부 확률(P(y│x))의 분포가 정규분포 대신 이항 분포를 따른다는 점이다.


실습데이터
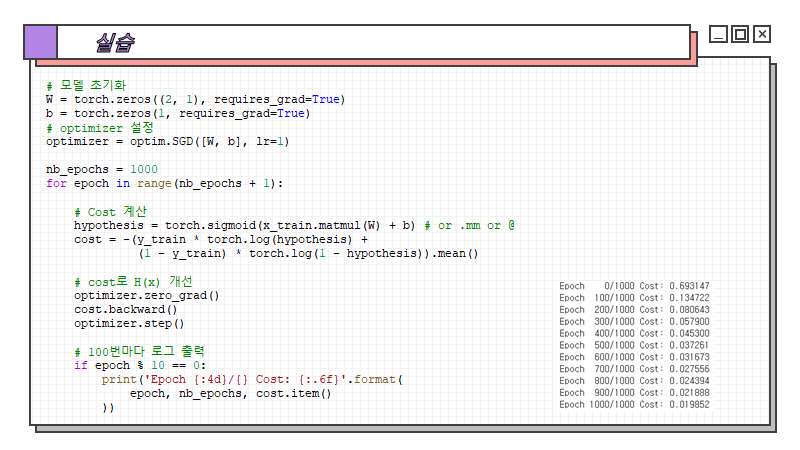
코드
'ML' 카테고리의 다른 글
| CNN[Convolutional Neural Network] (0) | 2021.02.11 |
|---|---|
| Restricted Boltzmann Machine(RBM) (0) | 2021.01.30 |
| SqueezeNet [모델 압축] 논문 리뷰&구현 [Matlab] (0) | 2020.11.17 |
| Decoupled Neural Interfaces Using Synthetic Gradients 요약 (0) | 2020.11.06 |
| Resnet (0) | 2020.10.09 |