2020/02/15
3.5기 3팀 최웅준,송근영,김정민
장소:한국항공대학교 중앙도서관
selective search 와 segmentation algorithm에 대하여 좀 더 스터디해보았다.
segmentation이란 무엇인가?
말그대로 이미지를 조각 조각 나누는 것이다. 이미지를 나눈후에 그룹화 시켜서 유사도를 구한 후 통합해 나아가는 것이 selective search의 목표이다.
Segmentation의 세가지 방법
픽셀 기반 방법: 이 방법은 흔히 thresholding에 기반한 방식으로 histogram을 이용해 픽셀들의 분포를 확인한 | 후 적절한 threshold를 설정하고, 픽셀 단위 연산을 통해 픽셀 별로 나누는 방식이며, 이진화에 많이 사용이
된다. thresholding으로는 전역(global) 혹은 지역(local)로 적용하는 영역에 따른 구분도 가능하고, 적응적 (adaptive) 혹은 고정(fixed) 방식으로 경계값을 설정하는 방식에 따른 구별도 가능하다.
Edge 기반 방법: Edge를 추출하는 필터 등을 사용하여 영상으로부터 경계를 추출하고, 흔히 non-maximum suppression과 같은 방식을 사용하여 의미 있는 edge와 없는 edge를 구별하는 방식을 사용한다.
영역 기반 방법: Thresholding이나 Edge에 기반한 방식으로는 의미 있는 영역으로 구별하는 것이 쉽지 않으
며, 특히 잡음이 있는 환경에서 결과가 좋지 못하다.
하지만 영역 기반의 방법은 기본적으로 영역의 동질성 (homogeneity)에 기반하고 있기 때문에 다른 방법보다 의미 있는 영역으로 나누는데 적합하지만 동질성을 규 정하는 rule을 어떻게 정할 것인가가 관건이 된다.
흔히 seed라고 부르는 몇 개의 픽셀에서 시작하여 영역을 넓혀가는 region growing 방식이 여기에 해당이 된다. 이외에도 region merging, region splitting, split and merge, watershed 방식 등도 있다.
픽셀기반의 segmentation을 자주 사용하기 때문에 정리해보았다.

픽셀 기반의 segmentation에서 흔히 사용되는 방식이 바로 thresholding이다.
특정 임계값을 정하고 그보다 작으면 검은색으로 그보다 같거나 크면 흰색으로 표시하는 방식이다.

<Threshold를 설정하는 방법>
임계값을 너무 낮게 혹은 너무 높게 설정하여 thresholding을 한 경우이다.


적절하게 임계값을 설정하기 위해 픽셀값의 누적분포를 알 수 있는 히스토그램을 사용한것이다.
Selective Search

<input image에 대하여 segmentation을 실행>
<segmentation을 실시한 영역에 대해 greedy한 방법으로 통합>
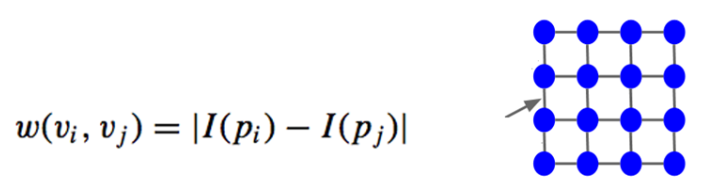
: 기본적으로 픽셀들 간의 위치에 기반한 가중치를 결정하기 때문에 greedy하며 위에 수식과 같이 자신의 상하좌우에 연결된 픽셀에 대해 생성

: C1과 C2의 영역을 가정한 그림
-
MInt : 그룹내의 연결된 가중치 중 최소 가중치를 의미
-
Dif : 그룹끼리 서로 연결된 가중치 중 최소 가중치 의미
서로의 가중치가 작을 수록 같은 라벨일 확률이 높다!
개념적으로 놓고 보았을 때 MInt보다 Dif가 더 작다면 집합안에서의 최소 연결 가중치 값(MInt)보다 집합 외부의 원소와 연결된 가중치 값(Dif)이 더 작다는 의미가 되며, 기본적으로 외부에 연결된 그래프가 더 가중치 차이가 더 클거라 생각할 수 있지만 오히려 MInt > Dif가 되면 이 내부끼리 연결한 것보다 외부로 연결한 값이 작다는 의미가 된다. 즉 그래프적으로 외부와 연결된 그래프 집합의 연결 가중치가 내부에 연결된 그래프들의 가중치보다 더 작기 때문에 더 유사하다고 생각할 수 있는 것이다.
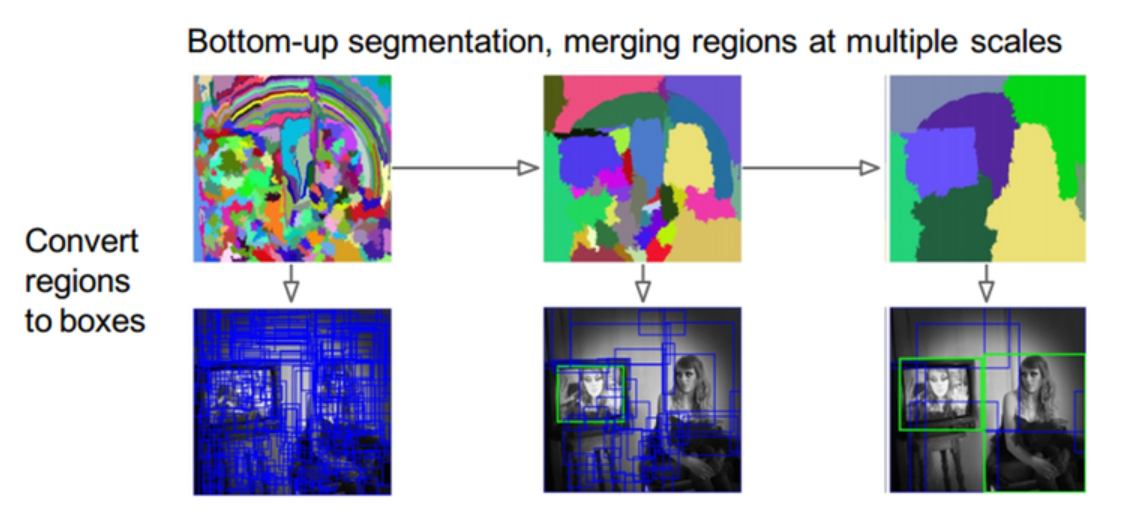
3번째 그림에서 보면 7~8가지 분류로 나뉘는 것을 볼 수있다. 이러한 후보군들에 대해서만 네트워크에 통과시켜 detection을 수행하여 계산 시간을 줄인다.
사실 RCNN에서는 위의 그림에서 보는것 처럼 7~8가지가 아니라 바운딩 박스가 2000개 이상 되지만 selective search를 수행하지 않았을 때 보다 훨씬 적은 숫자이기 때문에 계산속도가 빨라진다.
'ML > 머신러닝' 카테고리의 다른 글
| 신경망 구조를 이용하여 와인 분류하기[pytorch] (0) | 2020.02.24 |
|---|---|
| Pytorch를 이용한 Mnist 학습하기 (0) | 2020.02.24 |
| YOLO와 RCNN 분석 (0) | 2020.02.24 |
| Sliding window는 무엇일까?[object detection] (3) | 2020.02.24 |
| Hyperparameter vs Parameter 과 Bias and Variance Tradeoff 고찰 (0) | 2020.02.24 |