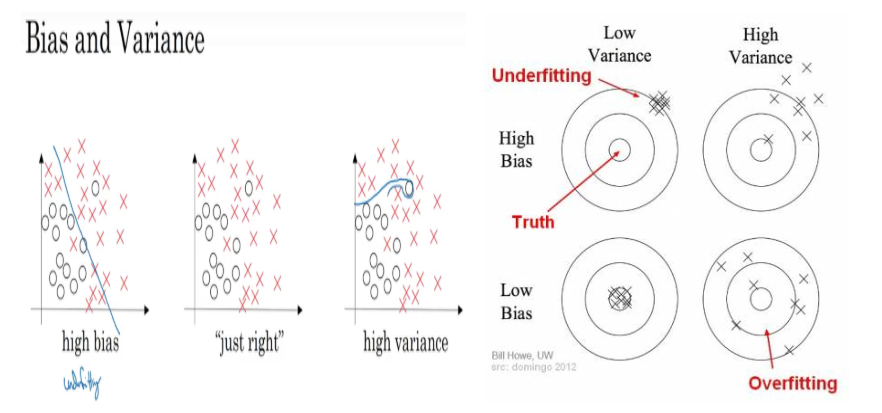
3팀-최웅준, 송근영, 김정민 회의 날짜 : 02/07 금요일 회의장소 : 능곡역 지노스 카페 회의 내용 : Sliding Window에 대한 팀원들 간의 질문이나 생각들이 가장 많이 겹친 부분이었으며 중요하다고 판단하여 이번 발표 주제로 선정하게 되었습니다. Sliding Window란 무엇인가? sliding window는 사진을 윈도 사이즈에 맞춰 나눈 다음 매 윈도우로 잘린 이미지를 입력값으로 모델을 통과해서 결과를 얻는 방법입니다. 기존 Sliding window의 문제점 기존 컴퓨터 비전 분야에서 신경망이 성공적으로 사용되기 전에는 간단한 선형 분류를 사용했었습니다. 사용자가 직접 특징을 정해주었고 분류기가 선형 함수를 사용하기 때문에 계산 비용이 저렴하였기 때문에 문제가 없었지만 슬라이드 윈..