이산확률변수 vs 연속확률변수

확률밀도함수(Probablity Density Function)[PDF]
연속확률변수에서 PMF(확률질량함수)를 사용하게 되면 모든값이 0일것이다.
그래서 확률밀도함수가 필요한데
확률변수 X가 모든 a,b에 대하여
P(a<=X<=b)=integral a~b (f(x)) dx 를 만족시킬 때,
X는 확률밀도함수(PDF) f(x)를 갖는다.
a=b 인 경우, integral a~a (f(x)) dx = 0
조건
f(x)>=0, integral ∞~∞ f(x) dx = 1
이산확률변수에서는 확률을 질량이라고 생각했었죠.
조약돌로 비유해서 조약돌의 질량이 다 더해서 1이라고 했었는데
연속분포에선는 더이상 조약돌이라고 생각할 수 없습니다.
이제는 바닥에 문질러 있는 진흙입니다.
진흙의 총질량은 1입니다.
밀도라 하면 부피당 질량이 생각 나겠죠
f(x)를 적분하면 확률이 나옵니다.
a=b 인 경우, integral a~a (f(x)) dx = 0
이었으므로 특정값을 가질 확률은 0입니다.
확률밀도함수는 확률이 아니다.
1보다 큰 값을 가진 함수를 적분해서 1이 나올 수도 있기 때문입니다
확률을 구하고 싶다면 확률밀도함수를 특정 범위에서 적분하면 됩니다.
ε은 그냥 작은게 아닙니다 엄청나게 작은겁니다
그 작은 범위 안에서 f의 값은 크게 변하지 않는다는 것입니다
그 작은 범위 안에서 f가 상수함수가 되는 겁니다
'밀도'는 무엇인가?



X가 PDF f를 가질 때

X가 CDF Fx(x)를 가질 때, PDF는 f(x)=F'x(x) 이다.
(연속적이지만 미분 가능하지 않은 함수가 존재합니다그러면 아주 복잡해지므로 연속확률변수라 함은 누적분포 함수가 미분 가능하다고 가정한다.)
<미적분학의 기본정리>

기댓값은 그냥 평균이죠
기댓값을 가지고는 분포의 폭이나 범위,분산에 대해서는 전혀 모릅니다.
그래서 분산이라는 개념이 필요한것이지요.
분산은 분포의 퍼짐의 정도를 알려줍니다.
분포들의 값이 그 분포의 평균으로부터 얼마나 떨어져 있는지를 알려줍니다.
기댓값에서 x를 빼는것부터 시작합시다.
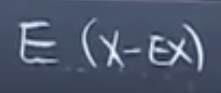
절대값을 쓰면 되지만 V 모양이 나와서 미분할 수 없습니다.
절대값을 쓰는 대신 전체를 제곱할 수는 있죠.
제곱을 하면 미분이 가능하고
피타고라스 정리가 생각이납니다.
기하학이 존재하게 됩니다.
하지만 제곱을 하게 되면 단위가 바뀌죠
x의 단위가 마일이라면 마일의 제곱이 단위가 되겠죠
그래서 표준편차라는 개념이 생겼습니다.
루트를 씌워줌으로써 단위가 돌아오게 되죠
분산이 수학적으로 다루기 편하지만 '해석'을 위해서 표준편차를 사용하는것입니다.
균등분포(uniform distribution)
Unif(a,b) -> 모수
균등분포는 특정 범위가 뽑힐 확률이 그 범위의 크기에 비례하는 분포입니다.
크기가 같은 두 범위가 있을 때 각 범위가 뽑힐 확률이 같아야 합니다.
범위 안에서는 확률밀도가 같아야 합니다.
확률밀도가 다르다면 균등하지 않겠죠
PDF f(X)=c
c는 뭘까요?
확률밀도함수를 적분했을 때 1이 나와야 합니다.
a~b까지만 적분하면 되죠
이외의 부분은 0이니까
c=1/(b-a)가 됩니다.
1/범위의 크기이 되는것입니다.
CDF
확률밀도 함수를 -infinite~x까지 적분하면 되지만
아까와 같이 a~b까지 적분해도 값은 똑같습니다.
a와 b값에 따라서 CDF값은 달라집니다.
기댓값 또한 a에서 b까지 PDF값 * x 값을 곱한것을 적분해주면 됩니다.
결과적으로 그냥 중간값이 됩니다.
균등분포인데 당연한 결과입니다.

무의식의 통계학
제대로 생각 안 해보고
그냥 대충 X를 X^2으로만 바꾸고
이런 생각 없이 하게 되는 것들을 말합니다.
확률변수 X의 확률밀도 함수를 알고
X의 함수의 기댓값을 구하려 할 때 생기는 일입니다
정석대 하자면 이 함수의 분포를 찾아야하지만
게으른 방식으로는 원래 X의 확률 밀도 함수를 그대로 쓰는것 입니다.

g(X)의 확률밀도함수를 구할 필요가 없습니다.
균등분포의 분산

E(u²)을 구하려면 무의식적인 통계학자의 법칙에 의해
u²의 확률밀도함수를 구할 필요는 없습니다
바로 u의 확률밀도함수를 써서 이 적분을 하면 됩니다


균등분포의 일반성(universality of the uniform distribution)
Unif(0,1) 를 통하여 어떠한 확률분포를 만들어낼 수 있다.
어떠한 분포든지 균등분포에서 그 분포로 전환할 수 있습니다.
대부분의 상황에서는 확률변수가 주어지고 누적분포함수를 구하지만
이번에는 특정 누적분포함수를 가진 분포를 만들어 보자.
F:누적분포함수
U∼Unif(0,1), CDF F를 가질 때 (F는 연속인 증가함수이다==>역함수 F^-1이 존재한다.)
정리) X = F^{-1}(U) 일 때, X∼F ===>역함수에 u를 넣은걸 X라고 했을 때 X가 F 분포를 따른다. X의 누적분포함수가 F가 되는것이다. 원하는 누적분포함수의 역함수를 구하고 확률변수를 넣으면 원하는 분포가 나오는것이다.
양쪽에 F를 취하게 되면 증명할 수 있다.
증명) P(X <= x) = P(F^{-1}(U)<= x) = P(U<=F(x))

'ML > 확률론' 카테고리의 다른 글
| 확률론 [Coupon Collector 문제] [보편성(universality)] [선형성(linearity)] (0) | 2020.09.02 |
|---|---|
| 정규분포 (Normal Distribution) (0) | 2020.08.26 |
| 포아송분포 (The Poisson distribution) (0) | 2020.08.19 |
| 수학스터디[확률통계] [기대값][기하분포][음이항분포] (0) | 2020.08.19 |
| 기댓값,지시확률변수와 선형성 (0) | 2020.08.12 |